Neetcode System Design
Summary: The neetcode system design course goes through everything you would need to know to take on a system design interview.
Not only is this useful prep for interviews, but it was a really fascinating curriculum.
Rating: 8/10
Videos
Computer Architecture
- Disk -> permanent, persistent memory. Slow read/writes, measured in milliseconds (100-1000 times slower than RAM). Inexpensive.
- RAM -> random access memory. Quick read/writes, measured in microseconds. Less overall storage. RAM contains code and data generally. Not persistent.
- CPU -> central processing unit. Brain of the computer. CPU mainly responsible for writing and reading from disk and ram. Plus, it executes code. High level code is compiled down into low level instructions that the CPU can interpret in machine language/ 0's and 1's. All a CPU knows how to do is perform computation
- Cache -> faster than RAM, but less memory. Reading and writing from cache is measured in nano (10^-9) seconds. Measured in MB. You need to be quite selective about what to cache, since it's so limited - use data that you read/write to frequently. Not persistent.
Application Architecture
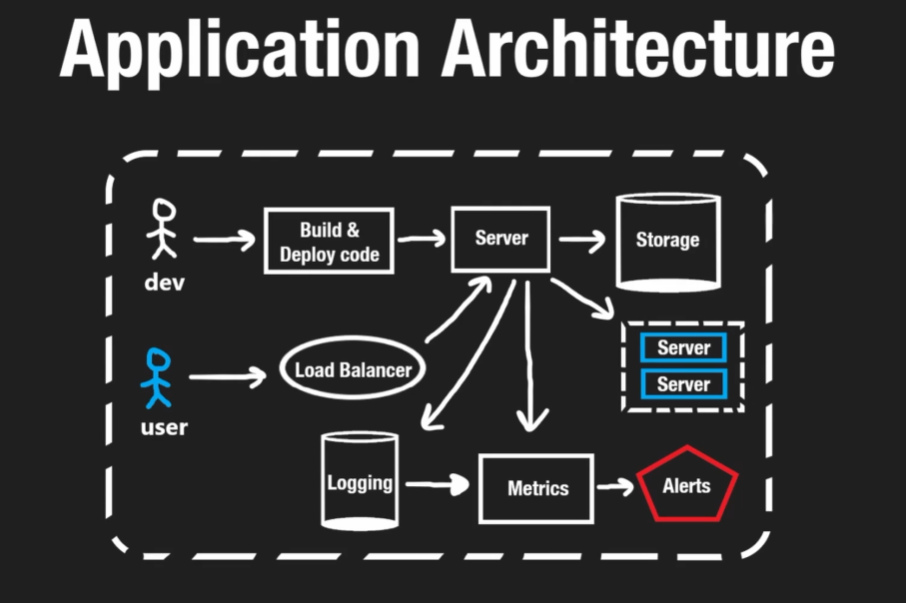
- As a developer, you build and deploy code that will run on a server somewhere
- Then you have your storage, which is stored on a different server (or set of servers)
- A user would make a request to our server, which would respond sending back (in the case of a web app) HTML, CSS, JS
- Vertical scaling would be making a single server more powerful
- Horizontal scaling would be adding more computers/servers
- With multiple servers handling requests, how do you know which server the user gets sent to? Load balancer will balance the load, with logic to send users to different servers depending on usage
- The server will hook into a logging service that will keep track of usage metrics
- We want push notifications from the metrics, which feeds into the alerts
Design Requirements
- Our goal is to design effective systems to solve huge problems
- There is often no perfect solution, but in a system design interview, it's about showing your thought process in analyzing the tradeoffs
- General design requirements are to
- Move data -> how do you get them around quickly/efficiently
- Store data -> how do you consider RAM vs. disk, for example?
- Transform data -> need to manipulate it to produce the right results
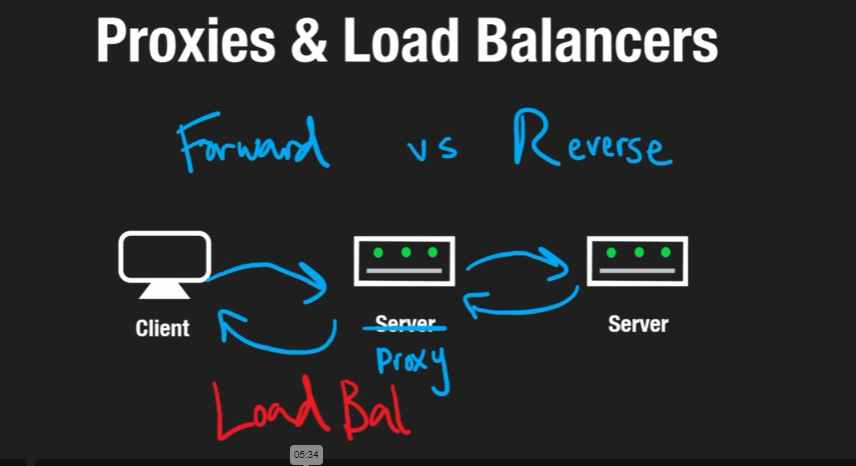
Proxies and Load Balancing
- Forward Proxy (standard)
- A client may not have access to a server, but the proxy server may have access. It bypasses the fact that you are the source IP
- Proxy can also block access to certain things. E.g. if all network requests flow through a proxy, the proxy may allow for a school to block access to youtube using a proxy
- VPN is a forward proxy
- Reverse Proxy
- The client doesn't know about the existence of the destination server
- CDNs are a reverse proxy - the CDN may make a request to the origin server, but the client doesn't know about the existence of it
- Load balancer is a reverse proxy - user makes a request, it hits the load balancer, we don't care what destination server is used, just that it gets what it wants
- Load balancer
- In interviews, you can kind of just say "let's throw a load balancer in there"
- Strategies
- Round robin - increments which server to use each time
- Weighted round robin - goes in order, with certain weighting (e.g.) first gets 50%, second 25%, third 25%
- Location based
- Hashing: hash the user id for instance and associate that to a certain server
- Layer 4 vs. Layer 7: 4 = TCP/IP -> looks at the network request, 7 = can look at application data. 4 -> more efficient, 7 -> more precise/powerful, more expensive
- What if load balancer goes down?
- You'd want to have multiple replicas of the load balancer
- nginx is a popular open source load balancer
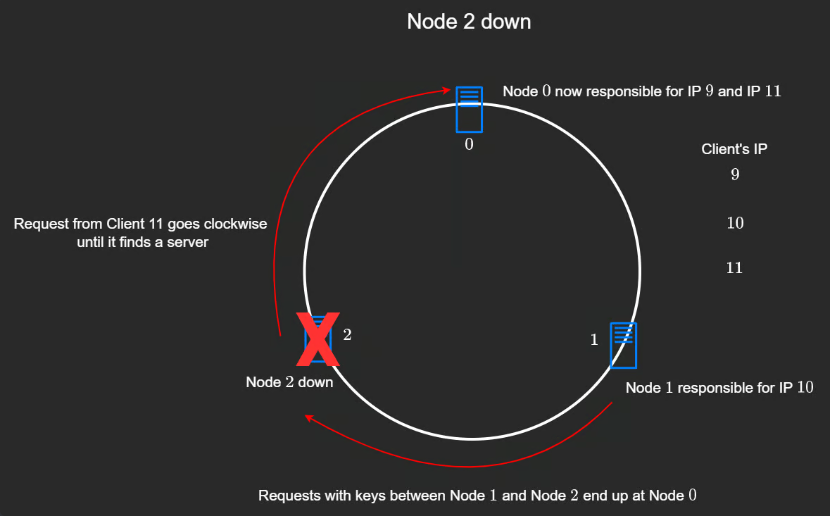
Consistent Hashing
- One way of balancing which server a load balancer sends a user to is to use a hashing function to route it
- With hashing, the same user will always be sent to the same server
- The server could then cache requests that the user sends without having to share the cached data with all the other servers, since they will never be used for that user
- One issue is - what if one of the servers goes down? Then the users have to be split amongst the remaining servers
- The solution to that is consistent hashing. It uses a ring-based structure, where if a server goes down, the requests it handled are reassigned to the next available server in a clockwise direction on the ring.
SQL
- Structured Query Language
- RDMS = relational database management system
- Disk is persistent memory that does not get lost
- Data structure for database is a B+ tree, which can have N children and multiple values, so the size of the tree is less, but the nodes and child relationships are greater
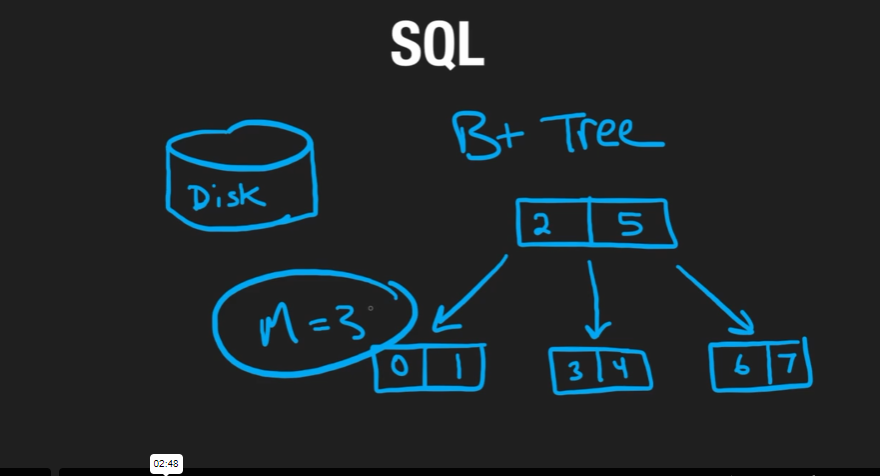
- Indexes are a way to sort the data
- Primary key uniquely identifies each record, where a record is a row. It could be an ID, or a name or phone number, whatever makes sense
- Table = the whole grouping of data, row = similar to excel row,
- Foreign Key = associates data in one table to data in another
- ERD = entity relationship diagram
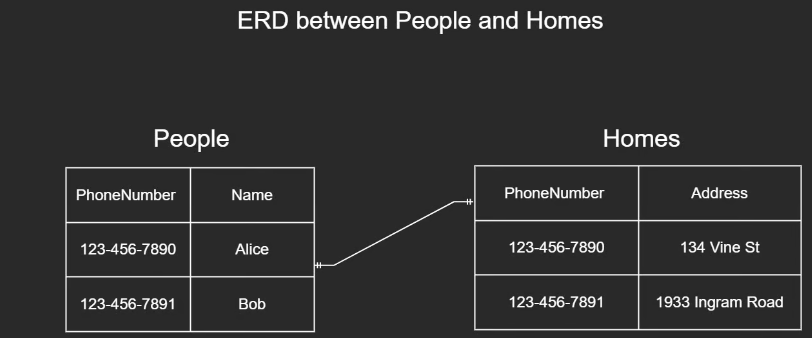
- JOINs are a way to combine records from two or more tables based on a related column between them
- Relational Databases folled what's called ACID = Atomicity, Consistency, Isolation, and Durability
- Durability - After a transaction successfully completes, changes to data persist and are not undone, even in the event of a system failure
- Atomicity - All changes to data are performed as if they are a single operation. All changes are performed or none of them are.
- Isolation - one transaction should be invisible to other transactions
- Consistency - ensures data integrity. Consistency in db's refers to adherence to predefined rules and contrains that maintainn the validity of the data throughout the execution of multiple transactions.
NoSQL
- Not only SQL
- Better name: non-relational
- No-SQL is great for scale. They can scale up more than SQL
- Key-Value
- Work like a hashmap
- Redis, memcached
- You could argue that they're not quite a DB
- Document Store
- Stores collections or documents
- They are essentially in JSON form
- Most popular is MongoDB
- Graph
- All about relations
- Keeping track of who follows who in social media, for instance, can be super hard. It is better stored in a graph
- Scale
- SQL has ACID requirements
- It is difficult to scale an ACID/SQL DB horizontally, storing half the data in one server and half in the other for instance.
- Eventual consistency - eventually DB's will match. For a small portion of time, people may see out of date values, but eventually they will be up to date. This allows horizontal scaling to work at scale, with a higher amount of read capacity
Replication and Sharding
- Replication
- When a single DB cannot handle all requests, replication comes into play
- Involves creating a copy of the DB called a replica
- Original DB is called leader or master, replica is the follower or slave
- Replication can occur asynchronously or synchronously
- Synchronous Replication
- Every write transaction on the leader is immediately replicated on the follower
- Cannot get from leader until replication is done
- Asynchronous Replication
- Delay in data replication
- Leader DB commits transaction and sends replication data to follower without waiting for the follower to acknowledge
- Can get from leader right away
- Leader - leader replication
- You can read and write to either/any of the DB's
- Likely to get out of sync and be inconsistent
- Can work reasonably well if they're location based. If one continent is on one DB and another on the other, it's ok if the data isn't up to date on the corresponding DB
- Sharding
- If you have a massive amount of data and duplication doesn't quite work, it makes sense to split the data apart and put them in separate DBs
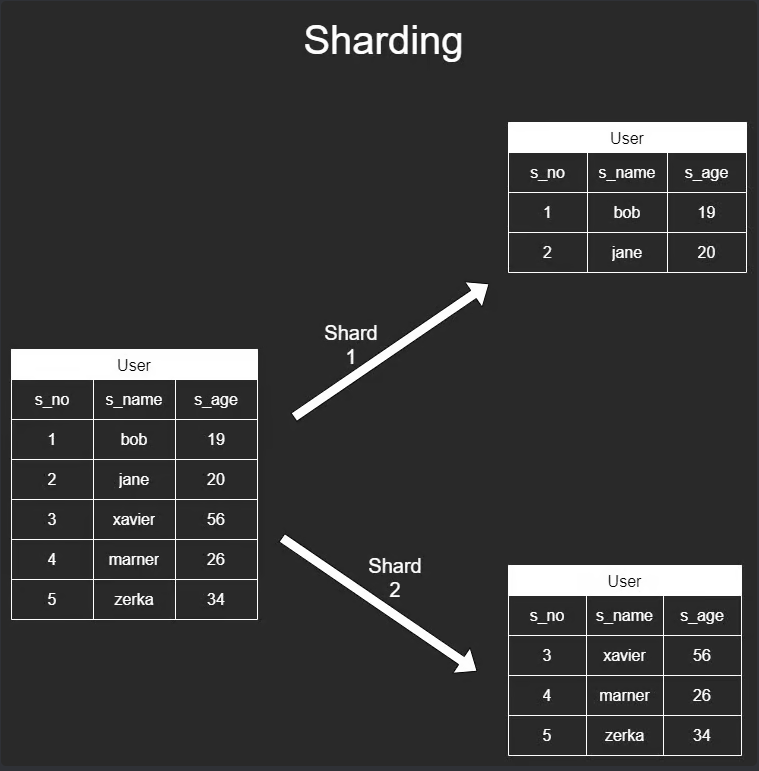
- Queries will be faster
- How do you decide what splits of data go where?
- Range based, using Shard Key
- Shard Key = based on values in row, row goes to different shard. I.e. A-L last names vs. M-Z last names go to different shards
- We lose consistency / ACID that comes with SQL when we use sharding
CAP Theorem
- CAP = consistency, availability, partition tolerance
- Partition = lack of connection between databases
- We need partition tolerance and to be able to continue tolerancing
- We must choose between consistency and availability
- Consistency = data consistency between the different DB's. Every read gets most up to date data
- Availability = having all of the databases available, even if the data isn't fully consistent
- You should favor either latency or consistency - waiting for up to date data or no data
- This is just about understanding the tradeo`ffs in designing a DB system
Object Storage
- Much newer than the Filesystem. More similar to filesystem than DB
- There is no tree structure like Filesystem, they are stored in a flat way, with hash map-like lookup
- AWS S3, Google cloud, azure
- BLOB - binary large object
- Images, videos
- You can write the files and read the files, but not edit
- Optimized to store a large amount of objects
- The interface for getting a file in object storage is HTTP, where you just ask for the filename
Message Queues
- If an app gets a number of events, and processing them immediately is not necessary, you can send them to a message queue
- From the message queue, the events will go to the server, which will process them. The queue waits for the previous one to process before sending the next one
- The queue is being stored on disk so that it is persistent
- Queue allows us to handle a larger amount of scale
- Events are generally handled FIFO
- The server can be pulling from the queue
- Or messages can push from the queue to the server
- Popular message queues:
- Kafka
- Rabbit MQ
- GCP Pub/Sub
Map Reduce
- If we need to scale up quickly, we need to split data across nodes
- Batch processing vs. streaming
- Batch = we are given the data up front. Imagine being given an entire book and being asked to count the instances of X word
- Streaming = get data in real time.
- Micro-batch processing - you process data every 30 s for example and it simulates streaming
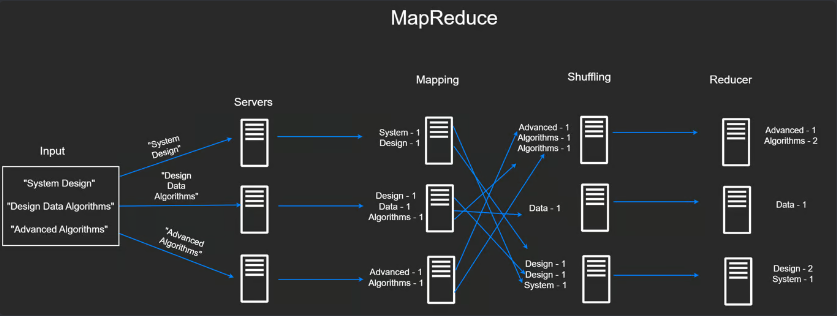
- Some portion of the data goes to one machine, some portion to another, etc.
- One Master node and multiple slave nodes
- Master node is tasked with managing the distribution of map reduce across worker nodes
- Worker nodes are venues where the actual data processing takes place. Master node assigns each worker a portion of the data and a copy of the MapReduce program
- Each worker node executes the map operation on the assigned data portion
- Shuffle and sort: worker nodes reorganize the key-value pairs so that all values associated with the same key are grouped together
- Reduce: Reduce operation preformed on each group of values, producing a final count for each word.
- Apache Hadoop is a MapReduce framework